This is the second part of our series on push technologies. In part one, we looked at Webhooks, explaining what they are, how they work, and use cases, as well as examples of APIs that support this style. In this part, we will look at PubSubHubbub, a closely related cousin to Webhooks.
When it comes to deploying the push (aka "streaming") architectural style of APIs, there is no single most accepted approach. In fact, there are several different approaches whose technical details vary from one another. One of those approaches—Webhooks—was discussed in Part 1 of this series. In this second part of this series, I'll cover PubSubHubbub, a closely related cousin to Webhooks.
What Is PubSubHubbub?
PubSubHubbubb is an API technology used to publish information on the Internet. The information can take any form: HTML, text, pictures, audio, or any other kind of content you can imagine. The idea behind PubSubHubbub is to push content rather than force clients to poll for it, which is typically how API implementations are designed to work. A setup includes these three elements:
- Publisher: Creates the information and sends it to a hub.
- Hub: Distributes the information to subscribers.
- Subscriber: Accepts the data feeds from the hub.
The original purpose of PubSubHubbub was to find a better way to distribute information than the polling techniques provided by Atom and RSS. Instead of waiting for clients to poll a server for updates, the hub automatically pushes the updates to the subscribers, keeping everyone up to date. Using such a push approach achieves the following goals:
- Reduces the resources the client/subscriber must use to keep updated.
- Ensures that the publisher can update clients/subscribers in a timely manner so that updates aren't old on arrival.
- Disconnects the publisher from the subscriber so that message traffic occurs asynchronously without slowing down either party.
PubSubHubbub relies on the use of topics. A subscriber can request a list of topics from the publisher and then decide which topics to subscribe to through the hub. The topic description includes the hub URL. In order to receive updates, the subscriber must run a Web-accessible server so that the hub can push updates to it using a client-side endpoint called a Webhook (described in Part 1 of this series).
A Webhook is a callback mechanism of the sort found in many applications that allows for asynchronous communication. When a PubSubHubbub-enabled app (the subscriber) places a subscription request, it also provides the connection details for the Webhook and the hub then uses that connection to feed updates to the subscriber. It's all based on a single event--an update by the publisher. Each such update triggers a push. You see PubSubHubbub used in a number of ways:
- Blogs, such as those powered by WordPress and Blogger
- News sites, such as those supported by CNN and Fox News
- Social media, such as MySpace and Medium.com
There are a number of reasons that PubSubHubbub is popular. However, the most common are:
- It's free
- It's open source
- It allows you to continue using polling as an alternative
- It doesn't break your current setup
How Does PubSubHubbub Work?
When working with PubSubHubbub, each party in the process has a specific role to play at a specific time in the sequence. The sequence can vary some, depending on how the configuration is set up. However, the following diagram shows a basic sequence of events that you see for most setups.

Creating a Subscription
Before anything can happen, a publisher must make the world aware that a particular piece of updateable content, called a topic, exists. In order to do this, the publisher communicates with a hub by sending it a form encoded POST with two fields:
hub.mode=publish
hub.url=<URL_OF_FEED>
Now that the hub is aware of the topic, it can accept queries on the part of subscribers. This process occurs in three steps. First, the subscriber polls the publisher for a topic as usual using a protocol such as RSS or Atom. Second, the publisher responds with a specially formatted message that includes two HTTP link headers, which look like this:
Link: <HUB_URL>; rel="hub"
Link: <URL_OF_FEED>; rel="self"
The hub URL is the location of the hub, such as https://pubsubhubbub.superfeedr.com/ or https://pubsubhubbub.appspot.com/. In fact, you can find a number of free PubSubHubbub hubs to serve your needs. It's also possible to provide this information as a single link header or to use HTML links like these:
<link rel="hub" href="HUB_URL">
<link rel="self" href="URL_OF_FEED">
Now that the subscriber has the required information, it can subscribe to a topic using a form encoded POST with three topics similar to this:
hub.mode=subscribe
hub.url=<URL_OF_FEED>
hub.callback=<URL_OF_WEBHOOK>
It's a good idea to use a different callback URL for each topic so that you can do things like monitor performance. In addition, using a separate callback for each feed URL reduces the complexity of writing code to handle new content. When the topic exists on the hub and the post is in the correct format, the hub sends a 202 response to the subscriber.
Of course, the system needs some means of ensuring that someone isn't playing a prank and subscribing to unwanted topics for unwary subscribers. With this in mind, the hub follows up a subscription request with GET request to the Webhook that the subscriber provides. The GET request includes these elements:
hub.mode=subscribe
hub.topic=<URL_OF_FEED>
hub.challenge=<HUB_GENERATED_STRING>
hub.lease_seconds=<TIME_BEFORE_SUBSCRIPTION_EXPIRES>
In order to keep the subscription action, the subscriber must respond within the hub.lease_seconds timeframe using the hub.challenge string and a 200 response. If the subscription isn't wanted, then the subscriber instead sends a 404 response with an empty message.
Updating a Subscription
After a subscriber successfully subscribes to a topic, the hub automatically pushes content to the Webhook each time the publisher indicates that new content is available. The following diagram shows the sequence of events that occur when new content becomes available.

In order to make the hub aware of new content, the publisher sends the hub a message like the one used to create the topic on the hub originally ; the hub.mode=publish and hub.url=<URL_OF_FEED> link headers described earlier. However, in this case, the publisher might want to use an array of URLs (if the hub supports it) to reduce the amount of network traffic. An array of topic links might look like this:
hub.mode=publish
&hub.url[]=<URL_OF_FEED1>
&hub.url[]=<URL_OF_FEED2>
Notice how the links are formatted in this case. You must add a set of square brackets after hub.url and separate the hub.url entries using an ampersand. There is no limit to the size of the array unless the hub defines one. Consequently, making all the required updates using a single call is possible.
After receiving the update event, the hub requests the content for each topic from the server and the server responds with the required content. With the hub updated, it's time to send the content to the subscriber Webhooks.
Unsubscribing
The process of unsubscribing from a topic is similar to subscribing. However, in this case, the subscriber sends a form encoded POST with with these three fields:
hub.mode=unsubscribe
hub.url=<URL_OF_FEED>
hub.callback=<URL_OF_WEBHOOK>
The only real difference is that the hub.mode changes. As with subscribing, the hub sends a challenge GET. However, it only includes these three fields:
hub.mode=subscribe
hub.topic=<URL_OF_FEED>
hub.challenge=<HUB_GENERATED_STRING>
To complete the unsubscribe process, the subscriber responds with a 200 response and a request body containing HUB_GENERATED_STRING value. Sending a 404 response keeps the subscription intact.
Why Use PubSubHubbub Instead of Webhooks?
Part 1 of this series describes how Webhooks functionality works and defines why you'd use it. Of course, PubSubHubbub relies on Webhooks to do its job, which may cause you to ask the question of why you even need PubSubHubbub; using Webhooks directly could be easier and certainly less complex. In fact, Part I provides you with a list of organizations that do use Webhooks in place of PubSubHubbubb. However, PubSubHubbub provides some significant benefits that you need to consider when creating your solution:
- Standards: There are currently no standards associated with Webhooks, which is considered a style, rather than a specification. Read more about the PubSubHubbub standard. The presence of a standard means that everyone can use PubSubHubbub in the same way, which makes development across platforms, vendors, and applications significantly easier.
- Automation: When using PubSubHubbub you have access to a simple REST API that makes automation of callbacks possible. When working with Webhooks, you generally need to provide the callback manually. Even if a particular service does automate the Webhook callback process, it's different from every other service due to the lack of standards.
- Discovery: Finding a resource is easy when using PubSubHubbub because it provides a standard discovery mechanism through HTTP link headers; Webhooks provides no standardized method for performing this task.
- Security: It's possible to create a denial of service attack with Webhooks because it doesn't support a challenge mechanism. Anyone can pose as the subscriber and the hub will never know it when using a Webhook. However, as noted earlier in this article, PubSubHubbub does provide a challenge mechanism that verifies the caller.
- Data Authentication: Even if you manage to somehow avoid a denial of service attack when working directly with a Webhook, it's possible that the data the subscriber receives is fake because Webhooks lacks mechanisms to protect the data. When working with PubSubHubbub you can verify the data content using an HMAC signature. In addition, PubSubHubbub relies on SSL data transfers.
How does PubSubHubbub Differ?
PubSubHubbub is a fat pinging protocol. (Another fat pinging protocol is XMPP subpub.) As noted earlier, when a publisher wants to publish new content, it first pings the hub to alert it to the new content. The hub then requests the content from the publisher and then sends that content to all of the subscribers. The problem with this approach is that the subscriber may not always want all of the content that the publisher has to provide. The traffic between the hub and the subscribers may be heavier than is necessary as a result.
An alternative is light pinging. The following diagram shows a quick overview of how light pinging works:
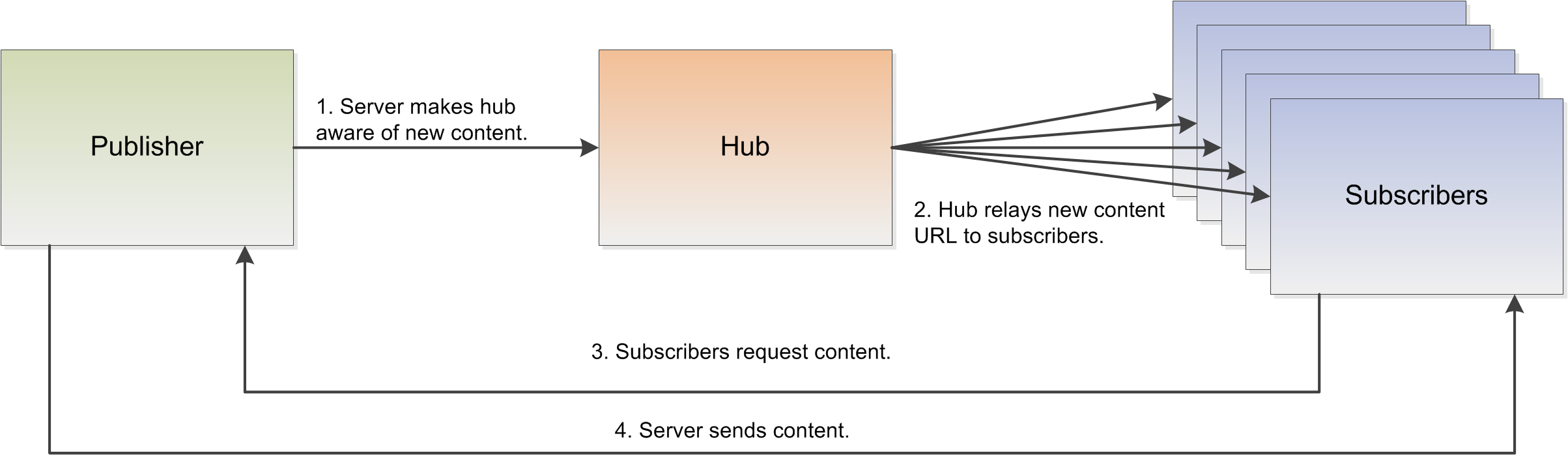
In this case, the hub sends only the URL for the content and the subscribers choose whether to request it from the publisher. This is the approach used by protocols such as rssCloud, XML-RPC pings, changes.xml, SUP, and SLAP. However, looks can be deceiving. In order to ensure that the light ping setup doesn't suffer from relay denial of service attacks, the first step actually requires three transactions, with the hub verifying that the publisher actually did send the URL. This means that the light ping process actually requires a minimum of six pings, which means it 33% slower than the fat ping approach.
The light ping approach also suffers from other issues. For example, instead of making just one request for content from the publisher, a light ping approach requires one ping for each subscriber that wants the content. The network bandwidth and caching requirements also tend to be greater. However, the biggest problem is that using a light ping approach means that the greater responsibility for managing content still lies with the publisher instead of being transferred to the hub. Consequently, the publisher can remain overloaded with requests.
Not all fat pinging approaches are the same. When comparing PubSubHubbub to XMPP subpub, the most important consideration is that PubSubHubbub is essentially asynchronous, while XMPP subpub maintains a persistent connection. This means that you can deliver information to subscribers (almost in real time) when using XMPP subpub, but at the cost of additional resources.
Calling a PubSubHubbub API
The previous sections of this article have discussed the techniques and underlying code used to create a PubSubHubbub feed, subscriptions, and updates. However, it might be nice to try things out before you devote a lot of time and effort to the task. Fortunately, most of the free hub sites provide you with some method for trying the technology. One such site is Google's offering. When you go to this site, you see a description of what you need to do, along with links that allow you to test both the subscribe and publish requirements as shown here.
The links are actually in the wrong order. You need to publish a feed first, and then subscribe to it. Here's the page for publishing a feed.
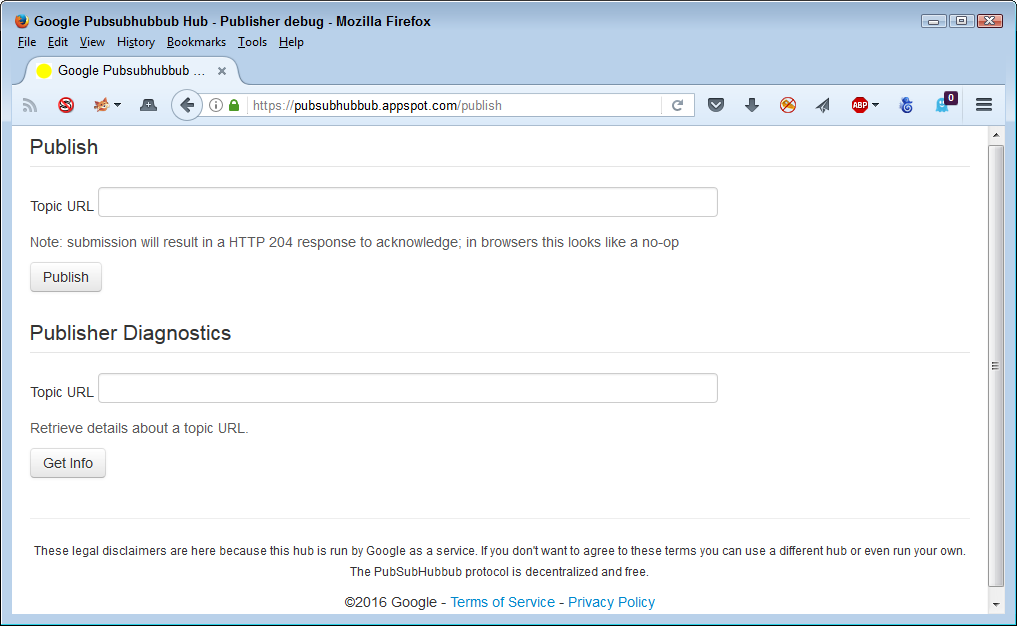
As mentioned earlier, you must provide a topic URL. The test page automatically provides the hub URL for you. You can verify that the publishing process worked as required by entering the topic URL again in the second field and clicking Get Info.
After you publish a topic, you can subscribe to it. Here's the subscribe page:
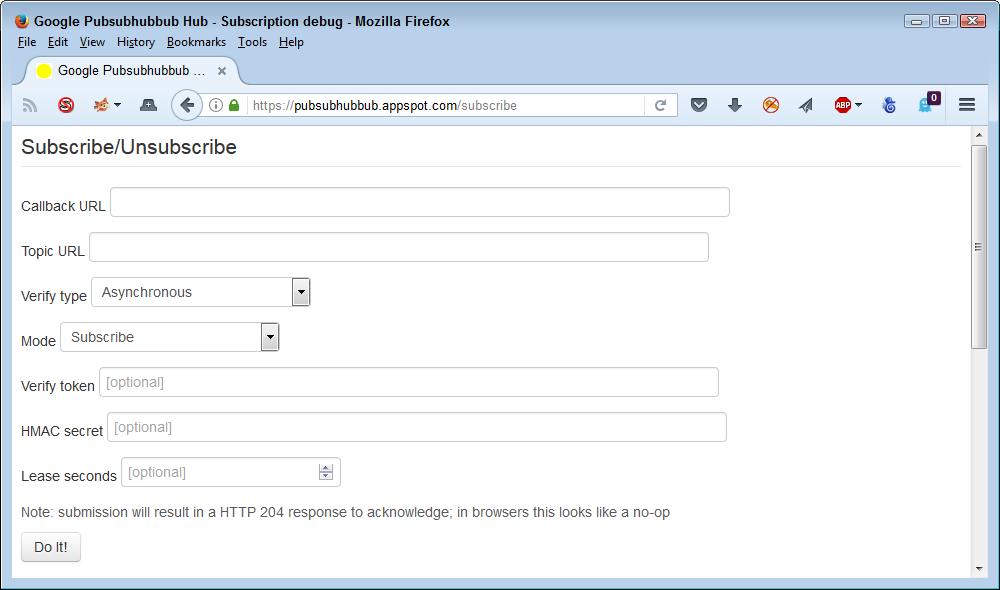
As you can see, you provide a callback URL for your Webhook, the topic URL, and the mode, which is to subscribe. Later, you can choose the unsubscribe mode to cancel the subscription. The Verify Type field should be asynchronous when working with PubSubHubbub. By following through this sequence, you can quickly see how PubSubHubbub works without investing tons of effort in the process.
This is part two of our series on push technologies. In part three we will provide a primer on WebSockets.