gRPC has become an important technology for implementing distributed software systems that need to run fast on a massive scale. In short, gRPC is an API framework that allows a program in one location on the internet to pass data to a distinct function in another program at another location on the internet for processing. While other API frameworks such as REST typically pass data from client to server and back again using text-based formats such as JSON or XML, under gRPC, data is passed between client and the server-side target function in binary format. The binary nature of gRPC's payloads is one of the contributors to its reputation for being faster than alternative approaches. Programs using gRPC can execute in nanoseconds as opposed to millisecond times which are typical when using text-based data.
gRPC has drawn significant interest from the development community since the specification was released as open-source by Google in February of 2015. (See Figure 1.)

Figure 1: According to Google Trends, there has been a growing interest in gRPC since it's release in 2015
Companies, large and small, are using gRPC, including noteworthy brands such as Slack, Microsoft, Condé Nast, Netflix, and Cisco, to name a few.
We at ProgrammableWeb believe that gRPC is a permanent fixture on the IT landscape. In fact, given the trends presented above, there is every reason to think that the adoption of the technology will continue to grow, particularly among enterprises that need blazing fast systems to meet their mission-critical needs.
Having a broad understanding of gRPC in the context of popular alternatives such as REST and GraphQL is essential for those companies doing or planning to do enterprise-level development of distributed systems at webscale. Presenting such an understanding of gRPC is the purpose of this article as well as the others that will follow in this series.
In this article, we're going to discuss how gRPC emerged on the landscape of distributed computing. Also, we're going to present an overview of the gRPC specification and show how the specification is implemented using a demonstration gRPC API created especially for this series of articles. Subsequent articles in this series will take a detailed look at specific aspects of gRPC, all the way from providing a detailed explanation of a complex demonstration gRPC application that contains both the client and server components to a set of in-depth interviews with a number of companies that have implemented gRPC as part of their technology stack. Also, we'll look at the problems and solutions of working with gRPC at scale. We're going to cover a lot. But, as with any journey, we need to start with the beginning and that beginning starts with understanding the need and history from which gRPC emerged. Essentially, the legacy of gRPC is all about distributing discrete functions among a network of computers.
The need for inter-process communication
The need to share computing resources has been around since the beginning of digital technology. Data sharing was the starting point. Companies needed to move data from one computer to another in order to process information in a way that was particular to each system. For example, it was not unusual for one bank to share a customer's loan history information with another bank wanting to determine credit-worthiness.
However, simply sharing data had limited use in terms of maximizing computing efficiency. It's true that time was saved by sharing the data, but still, each computer had to process that information using its own set of algorithms. Many times, a single algorithm was duplicated among many machines. Such redundancy was inefficient. If an algorithm was updated, that update needed to be propagated among all the machines using it. This is a risky undertaking. Thus, the notion of making it possible for a single computer to share its algorithms a.k.a procedures with other computers evolved. One-to-many sharing of a procedure came to be known as Remote Procedure Calls (RPC).
Remote Procedure Calls, the precursor to gRPC
The basic idea behind RPC is that a procedure (also known as a function) that is running on one machine can be shared by a number of other machines at different locations on the network. (See Figure 2, below)

Figure 2: RPC makes it possible for a computer to share a procedure (function) with other computers
The benefit of RPC is that it reduces system redundancy. When it comes time to upgrade the procedure, all changes take place in a single location. There's no need to copy the procedure onto other machines. Hence, upgrade activity is confined and controllable. As long as the public interface of the procedure (often called the "technical contract") — the structures of the data going into and coming out of the procedure — remains unchanged, the upgrade is opaque to those machines using the procedure. However, if the technical contract changes, which is known as "breaking the contract", problems can occur. Thus, while using RPC increases overall efficiency among systems, it is not risk-free. This is something to keep in mind when we examine the details of building and using gRPC APIs later on in this series.
Implementations of RPC
As mentioned above RPC has been around for a while. Traces of it can be found in Unix programming as early as the late 1970s and into the 1980s. Also, at the conceptual level, RPC appears in many technologies indirectly. For example, stored procedure technology which is a common way to embed functions in a database has its roots in RPC thinking.
Stored Procedures
Stored procedures are invariably mentioned in the same breath as relational database management systems (RDBMS). The general idea was that re-usable business logic for updating a database was kept within the general proximity of the database itself (often in the same RDBMS). The way a stored procedure works is that, instead of having a client program prepare data for storage and then execute the necessary INSERT or UPDATE SQL queries to store that data in the database, the logic for the insertion or update is stored as a named function within the database system itself. Listing 1 below shows an example of two stored procedures.
USE MyDatabase
GO
-- the stored procedure that validates data
CREATE PROCEDURE [dbo].[usp_customer_validate]
@first_name varchar(75),@last_name varchar(75), _
@gender varchar(6),@email varchar(75), _
@postal_code varchar(12)
AS
BEGIN
-- the validation code goes here
END
GO
-- the stored procedure that inserts data
CREATE PROCEDURE [dbo].[usp_customer_insert]
@first_name varchar(75),@last_name varchar(75), _
@gender varchar(6),@email varchar(75), _
@postal_code varchar(12)
AS
BEGIN
-- use the stored procedure usp_customer_validate
EXEC usp_customer_validate @first_name, @last_name, @gender, @postal_code
-- insert the data
INSERT INTO customers (first_name,last_name,gender,email,postal_code)
VALUES (@first_name,@last_name,@gender,@email,@postal_code)
END
GOListing 1: An example of stored procedures that runs on SQL-based database servers like those from Oracle or Microsoft
One stored procedure is named usp_customer_validate. The other is named usp_customer_update. The stored procedure usp_customer_validate validates the customer information passed in as parameters to the procedure. The stored procedure usp_customer_insert uses the usp_customer_validate stored procedure to validate the submitted customer data. Then, usp_customer_insert inserts a record into the table named customers. The table customers is part of a fictitious database named MyDatabase.
When a stored procedure is in play, clients need to do nothing more than establish a network connection to the database and pass the raw data onto the given stored procedure in the database. Listing 2 below is an example that shows how to call a stored procedure using .NET/C#.
var connectionString = "Server=(local);DataBase=MyDatabase;Integrated Security=SSPI";
using (SqlConnection sqlConnection1 = new SqlConnection(connectionString)) {
using (SqlCommand cmd = new SqlCommand()) {
Int32 rowsAffected;
cmd.CommandText = "usp_customer_insert";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add (new SqlParameter ("@first_name", "Dick"));
cmd.Parameters.Add (new SqlParameter ("@last_name", "Tracy"));
cmd.Parameters.Add (new SqlParameter ("@gender", "male"));
cmd.Parameters.Add (new SqlParameter ("@email", "dick.tracy@example.com"));
cmd.Parameters.Add (new SqlParameter ("@postal_code", "02122"));
cmd.Connection = sqlConnection1;
sqlConnection1.Open();
rowsAffected = cmd.ExecuteNonQuery();
}}Listing 2: C# client code that uses a stored procedure to insert data into a SQL-based database
The stored procedure then does the work of validating and storing the data. Data validation and storage are opaque to the client. All this work gets done internally within the database. Should the database's schema need to be changed, in this case, the SQL queries that are internal to the stored procedure are updated. The client's behavior doesn't change at all. This is essentially the dynamics of RPC. The function exists in one place on the network and is called by clients located elsewhere.
RPC and ERP
RPC also exists in Enterprise Resource Planning (ERP) systems. SAP, a major ERP technology supports a feature named, Remote Function Call (RFC). RFC is essentially RPC for SAP business systems. (See Figure 3 below.)
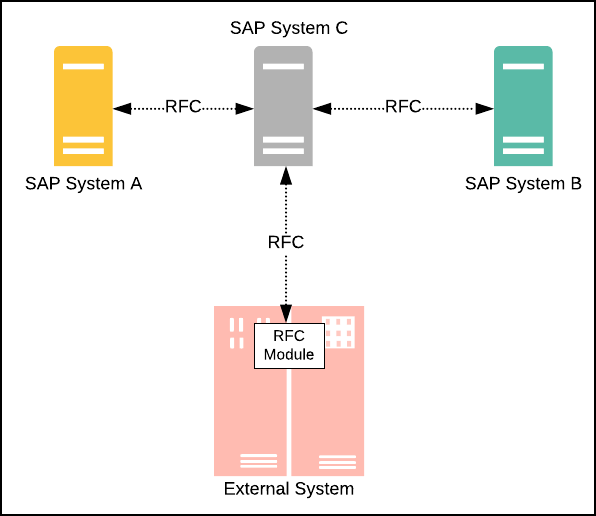
Figure 3: SAP's Remote Function Calls (RFC) is a variant of the RPC architecture style
RFC makes it possible for SAP systems to use functions that reside on external SAP and non-SAP machines provided the remote machine has the libraries required to support the RFC. Remote Function Calls under SAP are a good example of using RPC techniques to extend the computational power of a business system beyond the traditional capabilities of a typical ERP.
RPC under Java
Today one of the most common implementations of RPC is using a technology called Java Remote Method Invocation (Java RMI). Java RMI makes it so that any Java Virtual Machine-enabled computer (JVM) can expose Java functions to other machines that are running a Java Virtual Machine along with the Java RMI libraries.
Java RMI is essentially a client-server architecture but with a small twist. Instead of calling an endpoint directly as you would in a typical RESTful API request/response interaction on the Internet, clients need to get a reference to the RMI server that has a particular remote method of interest. (See Figure 4 below). There's a lot of back and forth that needs to happen even before a conversation can take place.

Figure 4: Java Remote Method Invocation makes it possible to access functions on a Remote server
Listing 3 below shows the code for Java class MyClient a portion of which was illustrated above in Figure 4. The class MyClient does the work of interacting with the Java RMI server.

Listing 3: The Java RMI client code that calls a remote method
The way that the client code works is that it gets a reference to the remote function by doing a lookup on the Remote Object Registry running on the server machine as shown above in Listing 3, line 8. Once a connection to the remote server is established and a reference is obtained from the Remote Object Registry, that reference is used to call the remote method (Listing 3, line 18) on the server using input data provided by the user at line 14. The result of the call is then passed back to the user at line 21.
Take the Hands-On Java RMI Tutorial
Take the ProgrammableWeb interactive tutorial on Katacoda to get hands-on experience working with the Java code that demonstrates the fundamentals of Remote Method Invocation (RMI).

As you can see even from the simple example shown above, Java RMI is a powerful technology that can make distributed computing a lot more efficient. But, it has a fundamental drawback. When using Java RMI both the client and server need to be speaking Java. For example, you can't easily have a .NET code call Java RMI code directly. In the case of .NET there are some workarounds such as JNBridge. But, overall Java RMI is intended to be a Java solution. Polyglot development support was not part of the product design.
Still, despite the lack of support for polyglot development out of the box, Java RMI brought RPC into the mainstream of distributed computing for commodity hardware environments and laid much of the groundwork for future generations of RPC, including gRPC.
However, while Java RMI was a net positive for RPC based API development, support for polyglot development was still an outstanding need, particularly as PHP, Python, and .NET gained popularity on the development landscape. This need was met by XML-RPC.
XML-RPC
XML-RPC, as the name implies, is a remote procedure call protocol that is built upon extensible markup language (XML). XML-RPC is a specification that is language agnostic. Any programming language that can process XML can support XML-RPC.
XML-RPC has been around for a while. The specification was first published in 1998. Although interest in XML-RPC has been waning in recent years, the protocol is still in use. WordPress uses XML-RPC to enable posting from external clients on cell phones and tablets. Also, Atlassian provides an XML-RPC interface into its Confluence product. (For a complete listing of APIs that support XML-RPC do a search on the term, xml-rpc in the ProgrammableWeb API directory.)
Simply put, XML-RPC clients use standard HTTP to send data to predefined functions that reside on an XML-RPC server. The lingua franca of the data exchange is XML that is formatted according to the standard defined by the XML-RPC specification. As mentioned above, XML-RPC is language-agnostic so it is entirely conceivable that a client program might be written in C while the server is programmed in Java. Such flexibility makes XML-RPC a viable alternative to language-specific RPC frameworks such as Java RMI and for many was a big step towards separating the concerns between client and server; a massively important tenet of the API revolution.
But, there is a price to be paid for flexibility. XML is a text-based format. Thus, relative to a binary approach, the data sent to and fro in data exchange is very bulky. While some XML-RPC API servers might accept data in a compressed format such as .zip or .rar, the XML-RPC specification describes the content-type of a request and response to be text/xml. This can be a hindrance for applications that need to exchange data at speeds on the order of nanoseconds. But, for applications that tolerate exchanges at the level of milliseconds, XML-RPC is still a workable API framework which is why some APIs continue to rely on it.
Get direct experience working with an XML-RPC by running the Simple XML-RPC demonstration project
All the examples shown below can be run using the Simple XML-RPC demonstration project found on ProgrammableWeb's GitHub repository here. Also, you can work with Simple XML-RPC directly by taking ProgrammableWeb's interactive lessons about XML-RPC on Katcoda.

Working with XML-RPC follows the same request/response pattern typical in any HTTP data exchange. The details of such an exchange are described in the sections that follow.
Anatomy of XML-RPC Request
Listing 4 below shows an example of the XML for a request that calls a procedure we named "ping" that's hosted on the same server that hosts an XML-RPC API.

Listing 4: A simple call to the ping method on the demonstration XML-RPC API server
Unlike REST, in which the only functions exposed by an API are the implicit HTTP verbs such as GET, POST, PUT and DELETE, the name of the function/procedure targeted by the call to an XML-RPC API is encoded directly into the XML structure sent to the API server. The parameters that go with the function are encoded as well.
In Listing 4 above, the tag <methodCall> as shown at Line 2 is the XML element that defines the method that is being called on the XML-RPC API. This <methodCall> tag is required by the XML-RPC specification. The <params> tag at Line 4 in Listing 4 is the element that will contain the parameters that are being sent to the API along with the procedure name. Each <params> element will contain one or many <param> elements. Each <param> will have a <value> child element as shown in Listing 4 at Line 6. The contents of the <value> element will vary according to the value's scalar type. In the case of Listing 4 above the scalar type of the parameter's value at Line 7 is a string. Thus, the string, I like ice cream, is enclosed in a set of <string></string> elements.
Table 1 below shows the six scaler types defined in the XML-RPC specification.
| Tag | Type | Example |
|---|---|---|
| <i4> or <int> | four-byte signed integer | -22 |
| <boolean> | 0 (false) or 1 (true) | 1 |
| <string> | string | I like ice cream |
| <double> | double-precision signed floating point number | -22.214 |
| <dateTime.iso8601> | date/time | 19980717T14:08:55 |
| <base64> | base64-encoded binary | eW91IGNhbid0IHJlYWQgdGhpcyE= |
Table 1: The XML-RPC scalar types
As mentioned above an XML-RPC data exchange follows the HTTP request/response pattern. A client sends the XML as an HTTP POST to the API's endpoint. Usually, there is only one endpoint on an XML-RPC server. The Simple XML-RPC Server demonstration project that accompanies this article listens for incoming XML-RPC requests at the HTTP root, /.
The server accepts the request and validates it to make sure that the request headers and the XML in the body are well-formed. The request is then passed onto the internals of the server for deserialization and processing.
IMPORTANT: Content-Length is required in the header of an XML-RPC HTTP request!
The XML-RPC specification requires that all HTTP requests to a XML-RPC API contain the attribute Content-Length in the request header. Content-Length must specify the size of the XML in the request's body in bytes.
Once processing is successful, the result will be serialized into XML that is sent back to the client in an HTTP response. Let's take a look at the details of the response.
Anatomy of XML-RPC Response
Listing 5 below shows an example of the XML received in an HTTP response from the XML-RPC API procedure named ping as described above. The XML is structured according to the format described in the XML-RPC specification.

Listing 5: A response to the ping method on the demonstration XML-RPC API server
The standard XML declaration is made at Line 1 in Listing 5 above. It's followed at Line 2 by the required XML-RPC element <methodResponse> that indicates that the XML is a response to a request made to the API. Line 3 has the <params> tag which will contain various response <param> elements. In each <param> element there will be a <value> tag. The value tag will contain another tag named according to the scalar type of the value. In this case, at Line 6 in Listing 5, there is only one returned parameter. It is a scalar type, <string> with the value ["I like ice cream"].
Notice at Line 6, the value of the string-returned parameter is formatted as a JavaScript array. Formatting the string as an array is completely arbitrary. Returning string parameters that represent an array is a decision made by the designer of the API library that you've chosen to help stand-up your XML-RPC API. It is just as possible that another library could return strings as an object, or just as a plain string. Thus, those using a particular XML-RPC API will do well to be aware of the format of string(s) returned from a call to an XML-RPC API.
Choosing an XML-RPC parsing library is a big decision
As part of our research for this series, we examined a number of libraries for implementing XML-RPC clients and servers. We discovered that while all libraries support the data exchange of XML according to the XML-RPC specification, the rendering and reporting of XML will vary according to the libraries used in the XML-RPC API implementation. For example, some libraries will transform the incoming XML into JSON or a language-specific object. These libraries publish both a client and server that are intended to be used together.
Thus, be advised that when selecting a library to work with XML-RPC, you may be locking yourself into a framework that might be hard to change later on.
Working with Arrays
XML-RPC supports arrays as a chain for child elements within the XML element <array> and then within the child element <data>.
Listing 6 below shows an example of the XML that describes a call to the XML-RPC procedure named add made on the Simple XML-RPC Server demonstration API. The XML passes an array of integers, in this case [0,2,2] to a procedure named, add. The array is defined in Lines 8 -19.
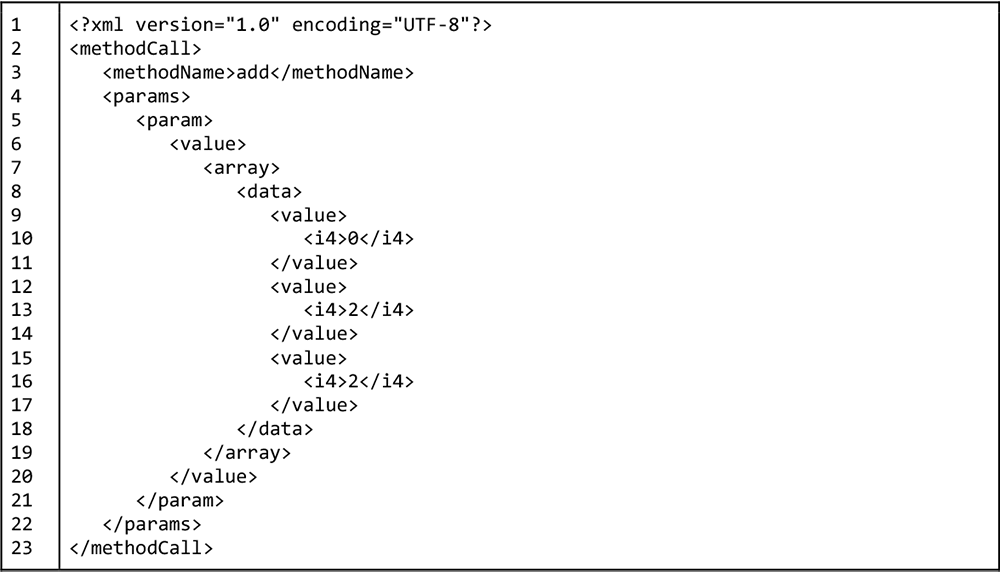
Listing 6: A call to a XML-RPC procedure, add, that take an array of integers to sum
Notice that there is a collection of <value> elements within the <array><data>... </data></array> sequence. Each <value> element contains an element that describes the data type of the value. Line 10 in Listing 6 above describes the value of the first element in the array like so: <i4>0</i4>. The element <i4> is defined in the XML-RPC specification to describe an integer. An array of strings would define each value as <string>.
Listing 7 below shows the XML response from the XML-RPC procedure named add.

Listing 7: The response from a XML-RPC procedure, add, that summed up an array of integers
In addition to submitting arrays, XML-RPC also specifies a way to submit named parameters to a procedure. This is done using the <struct> element.
Using structs and Named Parameters
Listing 8 shows an example of the XML that describes a call to the XML-RPC procedure chatter; one of the methods of the Simple XML-RPC demonstration API. The XML passes the parameters with the names message and limit as an XML-RPC defined structure. The parameter named message has the value "Hi there!". The parameter named limit has an integer value of 3.

Listing 8: A call to a custom procedure, chatter, that uses named values in a structure that includes two named parameters
Listing 9 below shows the XML response from the procedure call chatter. Notice that the XML shows the result of the call to be an array of XML-RPC struct. Each struct contains the message sent in the request as well as a value count, which reports the order of the struct in the array. Emitting the messages in an array and reporting the values message and count is the custom logic that is programmed into the chatter procedure.

Listing 9: XML-RPC API procedure, chatter responds with an array of values, each of which contains a struct
Why are we spilling so much ink on XML-RPC examples? As just demonstrated, the format for an XML-RPC array can have the result of creating voluminous XML content that can make HTTP requests and responses very big and thus slow to transmit and receive across a network. Developers planning to use XML-RPC need to be aware of this shortcoming. As mentioned above, the size of an HTTP request and response can be reduced by using .zip or .rar compression. Also, developers writing the logic that returns data in arrays can use paging to return arrays as a series of data chunks delivered over multiple HTTP conversations. The important thing is to be aware that arrays under XML-RPC can get quite large and as such, the large size will need to be accommodated.
XML-RPC brought a lot of flexibility to work the remote procedure calls and it allowed developers to work with RPC in a language-agnostic manner. And, the specification was easy to master. But, XML-RPC does have a significant drawback. The specification doesn't allow for defining custom XML elements. For example, you can't add an element <transactionId> to the XML message as a way to organize a number of HTTP request/response interactions under a single transaction.
It turns out that, at the time XML-RPC was being created in 1998, work on its successor was already in progress. This newer specification was the Simple Object Access Protocol (SOAP). SOAP was basically intended to take XML-RPC to the next level.
SOAP
Simple Object Access Protocol (SOAP) is very similar to XML-RPC in that it is a protocol for exchanging information encoded in XML against a procedure or service that resides on the Internet. The specification was made public in 1999 and is published by the W3C as an open standard.
Like XML-RPC, SOAP uses XML as its message format and supports HTTP as a transport mechanism. However, SOAP goes beyond the capabilities of XML-RPC in a variety of ways. First, SOAP can be used by a variety of transport protocols in addition to HTTP, for example, SMTP and FTP. (The typical pattern is to use HTTP for synchronous data exchange and SMTP or FTP for asynchronous interactions).
Another key difference is that SOAP uses a standard XML schema (XSL) to encode XML. In addition, developers can create their own XML schemas to add custom XML elements to SOAP messages. Finally, SOAP is typically used with the Web Service Description Language (WSDL). This means that developers and machines can inspect a Web service that supports SOAP to discover the specifics for accessing the service on the network as well as how to structure the SOAP request and response messages that the service supports. Discovery via WSDL makes programming Web services using SOAP messages a less burdensome undertaking.
The Basic Structure of a SOAP Message
At the basic level, the structure of a SOAP message is a hierarchy in which the root element is the <soap:Envelope>. This root element can contain three child elements. (See Figure 5, below.)

Figure 5: The basic structure of a SOAP message
The element <soap:Body>, as shown in the figure above is required. The elements <soap:Header> and <soap:Fault> are optional. If the element, <soap:Header> is present, it must be the first child element within the <soap:Envelope> parent. If the element <soap:Fault> is present, it must be a child of the element, <soap:Body>.
Table 2, below, describes the purpose of each element.
| Element | Description |
|---|---|
| Envelope | Describes the XML document as a SOAP message. |
| Header | Contains header information. |
| Body | Information relevant to the request or response being made |
| Fault | Contains information about errors that occurred during message processing. |
As mentioned above, SOAP messages are encoded in XML. Listing 10 below shows a SOAP message along with the HTTP header information embedded in the HTTP request. Lines 1 - 5 are the header entries in the HTTP request.

Listing 10: A web service request written in SOAP
Lines 1 and 2 are the usual POST and Host headers. Line 3 declares that the Content-Type of the request contains XML that is encoded according to the SOAP specification. Line 4 is the length of the request body, which is used in a way similar to the usage under XML-RPC.
Line 5 is the required attribute, SOAPAction that defines the intention of the SOAP request. Many times, web services that support SOAP will route the request to a service's internals based on the information in the SOAPAction header.
Lines 7 to 17 in Listing 10 above describe the SOAP message. Notice that two XML schemas are declared at Lines 8 and 9. The SOAP schema is bound to the namespace name, soap at Line 8. The namespace, m is defined at Line 9. The elements Envelope (Line 8), Header (Line 10) and Body (Line 12) are part of the soap namespace. The elements GetStockPriceRequest (Line 13) and StockName (Line 14) are custom elements associated with the XML namespace m.
The custom elements, GetStockPriceRequest and StockName, are specific to the Web service that provisions the target SOAP API. As one would expect, the Web service uses the information in these custom elements to process the contents of the SOAP message in a way that is particular to the service. Support for custom namespaces makes SOAP extensible for an infinite number of use cases in a controlled manner.
In terms of transport and consumption, the message shown above in Listing 10 can be part of a synchronous HTTP exchange between an HTTP client and web server. However, as mentioned above, SOAP is transport agnostic. Thus, the message could just as easily be sent as an email to an email server running under the simple mail transport protocol (SMTP). Intelligence in the email server would then pick up the SOAP message and process it. Upon completion, the processing intelligence sends the response as a reply to the originating email at a later point in time. A conversation via email is essentially an asynchronous exchange.
Listing 11 below shows a SOAP response to the request made in Listing 10 above. Unlike the XML-RPC specification which distinguishes between <methodCall> and <methodResponse> messages, the SOAP specification provides no such distinction in the namespaces schema. There is no <soap:Request> or <soap:Response>. Rather the distinction is left to XML elements defined in a custom namespace.
Listing 11, below shows a fictitious response to the GetStockPriceRequest made earlier in Listing 10. Notice the custom element <m:GetStockPriceResponse> at Line 13. This semantics of the element describes the message's body as a response. The element's name is GetStockPriceResponse is arbitrary. It could just as easily have been named TickerResponse. The important thing to understand is that request/response distinction is delegated to the elements defined in the custom XML namespace.

Listing 11: A web service response written in SOAP
Also, notice that the elements shown at Lines 14-16 in Listing 11 above are part of the custom namespace m and contain information that is semantically relevant to the response. This is another example of using a custom namespace to extend the meaning of a SOAP message. Combining the standard SOAP schema with custom schemas makes SOAP a very versatile format for data exchange.
Pros and Cons
There are a lot of benefits for using SOAP. The protocol uses HTTP as a transport, But, it can also use protocols such as SMTP and FTP. SOAP supports reflection via WSDL and it is language agnostic, which is a significant benefit in large companies that support a variety of programming languages yet need to have a lingua franca of message exchange. Also, at one time in the early days of Web services, SOAP was very popular. Thus, there are still a lot of legacy SOAP implementations that need to be maintained, which makes it a very attractive way to make money.
If COBOL taught us anything, it's that old code doesn't die. It just slowly fades away after decades upon decades of maintenance. There will be a significant demand in the foreseeable future for developers to maintain and extend the existing SOAP code. As the supply of SOAP developers dwindles, the remaining developers who are well-versed in SOAP will be able to command premium salaries. The law of supply and demand favors SOAP developers.
Like any API architectural pattern, however, there are disadvantages to using SOAP. The main disadvantage is that because SOAP is based on XML which in turn can be very verbose (especially with custom namespaces), you have to move a lot of text over the network to get things done. Also, the SOAP specification takes time to master. The protocol has a fine degree of detail. For example, while the specification supports the notion of using SOAP messages to do remote procedure calls, actually implementing RPC under SOAP requires mixing standard SOAP elements with custom elements. The custom elements need to provide the RPC semantics that the SOAP specification requires but that the SOAP schema doesn't provide. In other words, you cannot implement real-world RPC using only the XML elements defined in the standard SOAP schema. You need to create custom elements to fill in the gap.
SOAP is still alive and well
One of SOAP's strengths is the combined power of extending the format using custom namespace and the strong typing that goes with custom namespacing. These are attractive benefits, so much so that new SOAP APIs are still being released, particularly for those API in which data integrity is a paramount concern.
The final disadvantage is that SOAP is old. It's been around since 1999. Back when the Internet was young, SOAP brought a lot of power to Web service-based programming. But now billions of people and more importantly, billions if not trillions of machines in the IoT universe use the Internet every minute of every day. The bulkiness of the protocol is an impediment to achieving the speeds needed to operate at this degree of web-scale.
SOAP met a real need at one time. But that was then and this now. Today enormous amounts of data need to move over the network at lightning-fast speeds. People want to view their movies now, not in an hour. Stock trading takes place in terms of nanoseconds, not milliseconds. Faster, more efficient protocols beyond the capabilities of SOAP and XML-RPC are required. One protocol that meets the need at hand is gRPC.
The emergence of gRPC
As mentioned above, gRPC was created at Google to meet the company's need for speed for code that runs cost-efficiently at web-scale. While it's true that all companies want code that executes fast, Google's needs redefine the word fast. Critical to Google's operation is its ability to index the entire Internet. In order to perform such a feat, three things are needed: first lightning speed, vast scale, and extraordinary machine efficiency. Google has the computing horsepower and it has the networking capabilities to achieve its goal. Where things get touchy is around the speed by which data that gets passed around between applications.
Meeting the Need for Speed
For better or worse, most of the data that get passed back and forth on the Internet is structured according to text-based formats. HTML is text-based as is XML. These are bulky formats in that they require opening and closing tags. For example, just to transit the ten characters that make up the name, John James, in a structured manner via standard HTML requires 151 characters as shown in Listing 12 below.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
<div id="first_name">John</div>
<div id="last_name">James</div>
</body>
</html>Listing 12: HTML is a bulky format for transmitting information
Transmitting the same information in XML requires ninety-four characters which is fewer than the number of characters in HTML. Still, it's bulky. (See Listing 13 below.)
<?xml version="1.0" encoding="ISO8859-1" ?>
<name>
<first>Jone</first>
<last>James</last>
<name>Listing 13: XML offers a more concise way to structure data than HTML
JSON, another popular text-based data format is even more concise than XML. Transmitting the name, John Doe in JSON requires only 47 characters as shown in Listing 14 below.
{
"first_name": "John",
"last_name": "James"
}Listing 14: JSON is intended to be a concise text-based data format
While JSON is a more concise format than either HTML or XML, in terms of Google's need for speed and efficiency, it's still too bulky. Table 3 below illustrates the actual bit count of the name John James as expressed in the HTML, XML, and JSON shown in the examples above. (Remember, each character is 1 byte which equals 8 bits.)
| Example | Word Count | Bit count |
|---|---|---|
| Listing 4: HTML | 151 | 1208 |
| Listing 5: XML | 96 | 768 |
| Listing 6: JSON | 47 | 376 |
Table 3: The number of bits required to transmit the name, John James according to first name and last name.
When you consider that the actual bit count for the 10 characters that make up the name — John James in only 80 bits of white space characters included — all of the formats illustrated above in Table 1 are overwhelmingly large when you have needs on the order of Google's. Especially when it comes to the packaging and transmission of data across a network. Something better was needed. That something better is Protocol Buffers.
In gRPC, all data is transmitted in binary format. Information is serialized into a compact collection of bits and then sent over the network. Then, when the bits reach the target destination they are deserialized back into text. The binary format used in gRPC is protocol buffers. Using protocol buffers make data fast to transmit, but it does come with a cost and that cost is incurred due to the overhead that comes with describing data.
The Cost and Benefits of Binary Data Formats
When you take a look at the HTML, XML, and JSON shown in the listings above you'll notice that most of the text in the examples is used to describe the data. Take a look again at the JSON example:
{
"first_name": "John",
"last_name": "James"
}The name John James takes ten characters including white space. But, the JSON representation of the name takes 47 characters. Those extra 37 characters are used to describe and structure the data. It's necessary. Without that description, we have no idea what the data is about. We don't know if the content of the JSON is a name, let alone if James is a first name or the last name. Thus, data descriptions are essential in terms of processing the data.
HTML, XML, and JSON are known as self-describing formats. The format tells you what the data is about just by looking at it. In the JSON example above, we know that John is the first name and James is the last name because the JSON properties first_name and last_name describe the fields directly.
Self-describing data formats are very useful but they are also very expensive to transmit over the network due to the added characters required. But, what if we used a data format that was not self-describing? What if both the source and the target of the information being transmitted had a "reference manual" by which one knew how to determine the segmentation and order of fields in the collection of bits being sent over the network? Removing self-description from a data structure dramatically reduces the actual size of the data that needs to move over the network.
The reduced size that a binary data format supports is the essential benefit of Protocol Buffers. But there's a tradeoff. With self-describing data, you do not need a "reference manual" common to both the source and the target. With Protocol Buffers you do.
Using Protocol Buffers is more costly in terms of the added complexity and processing required to serialize/deserialize the data and decipher meaningful information from the binary message. On the other hand, the benefit is that data moves faster once it's on the wire. When designing gRPC, Google chose to accept the costs to get the speed. When you index the Internet as a way of life, nanoseconds count. Hence, foundational to gRPC is the use of the Protocol Buffers binary format for transmitting data over the network.
Binary serialization formats have been around for a while
Protocol buffers are one of the many formats for binary encoding. There's also Apache Thrift which is used by Facebook in some of their back-end services. It's also used by Evernote to sync notebooks between client devices and Evernote's cloud. Also, there's Apache Avro which is used in the distributed processing framework, Hadoop. There are other binary formats. You can read a complete list of various data serialization formats on Wikipedia, here.
Today the need for the sort of increased speed offered by binary data formats has gone well beyond Google. As more people want more data at an increasing rate, more companies are willing to accept the technical overhead that goes with supporting gRPC in order to reap its benefit. In short, gRPC is becoming mainstream. Knowing how it works and to what applications its best suited is no longer a luxury. It's essential.
The gRPC Framework in a Nutshell
gRPC is an API framework that supports point-to-point function calls over HTTP/2 (essentially, version 2 of the World Wide Web). The important thing to understand about gRPC is that it's a specification that can be implemented in any programing language capable of supporting the requirements described in the gRPC specification. As of this writing there are implementations in a variety of languages, including but not limited to GoLang, C#, C++, Java, Objective-C, Ruby, Node.js, and Python just to name a few.
Using HTTP/2 makes it so that gRPC supports bi-directional streaming (a feature of HTTP/2). While gRPC allows standard request/response interactions between client and server, gRPC's dependence on HTTP/2 means that a client can transmit data to a server in a continuous stream of bits and vice versa. Also, gRPC makes it possible for bi-directional streaming to occur simultaneously (another feature of HTTP/2). The result is that a client can stream data continuously to a server while that same server concurrently streams data back to the client.
Another key benefit of HTTP/2 has to do with the allocation of system resources, particularly on Linux. As you will see in ProgrammableWeb's case study regarding Ably.io's implementation of gRPC, HTTP/2 provides a workaround to the network connection limitations imposed by the Linux kernel. In HTTP/1.1, each request and response requires a sole connection. HTTP/2 supports multiple request/response exchanges over a single connection.
The other key point about gRPC is that as described previously, all data gets passed between client and server as binary data using Protocol Buffers. The definitions of the data types, known in gRPC parlance as messages, as well as the functions published by a gRPC API, are described in a .proto file which is known to both the client and server. You can think of a .proto file as the aforementioned "reference manual" that is used by both the client and server. Using a common .proto file is similar to the pattern of using an IDL (Interface Description Language) to facilitate inter-process communication between different languages in an RPC interaction. In fact, the .proto format is derived from IDL.
Figure 6 below illustrates the basic concepts behind gRPC. Notice that client and server communicate over HTTP/2 and that information can be exchanged as a single request/response event or as a continuous stream.

Figure 6: The schema that describes the gRPC API is defined in a .proto file that is shared by both client and server
Also, notice that both the client and server reference the schema in a common .proto file to determine the structure of the messages that are to be serialized and deserialized between client and server. (In upcoming installments in this series we'll discuss the different techniques that are used to allow a gRPC server and its clients to share the schema defined in the .proto file.)
In addition, the gRPC schema in the .proto file contains the function signatures that are published by the server. The client will use this information to pass messages to a particular function, according to the published function declaration. The following is an example of a function declaration that would be defined in a .proto file.
rpc Add (Request) returns (Response) {}WHERE:
rpc is a reserved protocol buffers keyword indicating that the function is a remote procedure call
Add is the name of the function
(Request) indicates that the function has a single parameter of custom message type, Request
returns is a reserved protocol buffers keyword indicating prefacing the return type of the function
(Response) indicates that the function will return a custom message of type, Response
What is the difference between a function declaration and a function implementation?
A function declaration describes the function name, the function scope, the input parameters, and the return type. Separating function declaration from function implementation varies according to language. In Java, a function declaration is done in a Java interface like so:
public interface Communicable {
public String ping(String message);
} Then, once the function is declared in the interface, it's implemented in a Java class, like so:
public class Talker implements Communicable{
@override
public String ping(String message){
System.out.print("I am going to return the message: " + message);
return message;
}
} The pattern of separating function declaration from function implementation carries over at the conceptual level in gRPC where the function declaration is done in the .proto file, while implementation is done according to the framework and language used to program the .proto file into actual behavior. For example, the function add(), described in the .proto file like so:
rpc Add (Request) returns (Response) {}Can have an implementation using the Node.js gRPC library as follows:
function add(call, callback) {
const input = call.request.numbers;
const result = input.reduce((a, b) => a + b, 0);
callback(null, {result});
} As you can see, working with a .proto file is an important aspect of working with a gRPC API. So let's take a detailed look at the .proto file that defines the Simple Service demonstration project that accompanies this article. Understanding the specifics of the protocol buffer's language specification is important for anyone intending to work with a gRPC API.
You can find the current version of the complete Protocol Buffers Language Specification at https://developers.google.com/protocol-buffers/docs/reference/proto3-spec
Defining the .proto File
Listing 15 below shows the contents of the protocol buffers .proto file that is the foundation of this article's demonstration API, Simple Service. Line 1 is the syntax statement that declares the version of the language specification used. As of this writing, the current version of Protocol Buffers is Version 3. But be advised, there are a lot of gRPC APIs in force that uses Version 2.
Listing 15, line 3 is the package declaration where simplegrpc is an arbitrary name for the package. A package is similar to a namespace in C++, C# or Java. It's a way of organizing messages and functions in the .proto file under a common name.

Listing 15: The .proto file that describes a simple gRPC API
Lines 5 - 43 describe the messages that the Simple Service API supports. An interesting thing to note about the message declaration format is the use of a field index number when defining a field in the message. Let's take a look at the reasoning behind the use of index numbers.
Understanding Field Indexing in Protocol Buffers
Take a look at the description for the message type ChatterRequest.
message ChatterRequest {
string data = 1;
int32 limit = 2;
}Notice that ChatterRequest has two fields, data and limit. The data field is of type string. The field limit is of type int32. These are standard types defined in the Protocol Buffers language specification. Also, notice above that the field data is assigned an index number of 1, and limit is assigned an index number of 2. Using index numbers is particularly noteworthy because unlike a self-describing format such as JSON where field naming is explicit to the data structure, binary data in a serialized protocol buffer message lacks direct field naming. All that's known is the field length and hence the value assigned to the field as well as the index number.
Just knowing only a field's value and its index number is not useful. You need a way to determine what the field represents. This is where the .proto file comes into play. Imagine a message definition like so:
message Birthday {
int32 day = 1;
int32 month = 2;
int32 year = 3;
}Each field contains a number. However, were we to examine an instance of a Birthday message in pure binary format, how will we know what each number in the message means? Does that number represent a month? A year? A day?
In order to decipher the meaning behind a field's value, we use the .proto file as a "reference manual". In the Birthday example above, when it comes time to deserialize the binary message into a text format, all the logic has to do is look-up the field according to the known index number as defined in the message definition within the .proto file. Then the logic extracts the field name according to the field index number. All that's left to do to create a textual representation is to combine the field name and the field value. Figure 7 below illustrates the concept of field name determination using index number lookup.
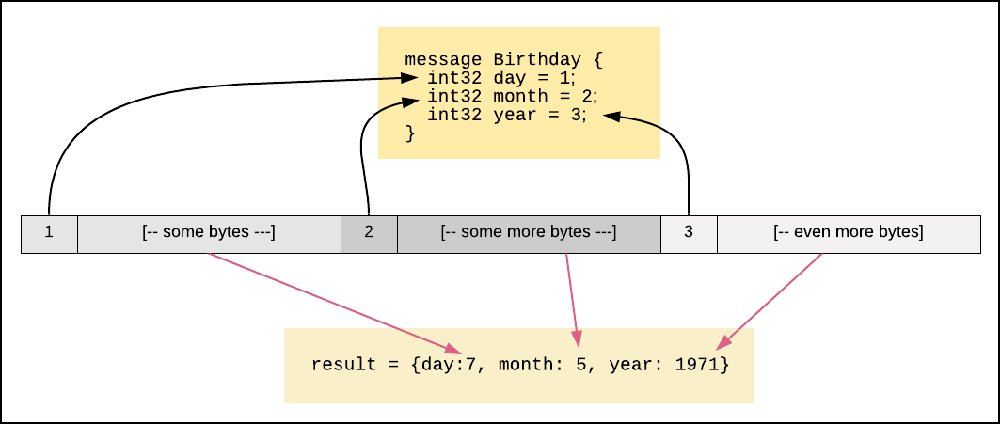
Figure 7: Binary encoding under Protocol Buffers uses index numbers to segment and identify fields
You can read an in-depth explanation of Protocol Buffers encoding at: https://developers.google.com/protocol-buffers/docs/encoding
Let's move on to how services are defined within the .proto file.
Understanding Service and Method Definitions
Line 45 in Listing 5 above is the beginning of the service declaration section. gRPC organizes all functions under a service name. In this case, the service name is SimpleService. Lines 46 - 57 define the signatures of the functions published by the API. The .proto file defines six functions, Add, Substract, Multiply, Divide, Ping, and Chatter. The implementation of these function signatures is programmed later according to the language framework used. The Simple Service demonstration API is implemented using the Node.js platform so the logic for the functions will be programmed in server-side JavaScript files.
The functions Add, Subtract, Multiply, and Divide do as their names imply. Each function takes a Request message as a parameter, defined at line 5 of Listing 6 shown above. (Naming the message Request is arbitrary.) The Request message has a single property (numbers) which is an array of floating-point values. Each function will perform its implied operation on the array of numbers submitted according to their order in the array. For example the function Add([2,3,4,5]) returns a Request message like so: {"result": 14} as shown in Figure 8 below.

Figure 8: The Simple Service Add function sums up all the numbers in the submitted array using BloomRPC as a gRPC client application
The function Divide([2,3,4,5]) returns the following Request message: {"result": 0.03333333333333333}. (See Figure 9, below.)

Figure 9: The Simple Service Divide function divides the numbers in the submitted array according to each number's position in the array
The function, Chatter (ChatterRequest) returns a stream of ChatterResponse messages as shown below in Figure 10.

Figure 10: The Simple Server function, Chatter returns ChatterResponse message in a stream
Streams vs Arrays
As you can see from Figure 9 above, streaming is a powerful feature of gRPC and one that deserves additional attention.
Read ProgrammableWeb's in-depth article that describes how to build a streaming API under gRPC here: https://www.mulesoft.com/api-university/how-to-build-streaming-api-using-grpc
Let's take another look at the function signature for (ChatterRequest) as defined above in Listing 5 because it's a good example of the implications of streaming under gRPC.
rpc Chatter (ChatterRequest) returns (stream ChatterResponse) {}Notice how the stream is declared after the returns clause, (stream ChatterResponse). This means that an HTTP/2 connection will be established and a series of ChatterRequest messages will be sent or "streamed" over the wire for the duration of that connection. Depending on how the function is implemented, that connection will be closed once the stream transmission is complete. Or, it can be left open. It's up to the programmer.
If I wanted to make it so that Chatter (ChatterRequest) aggregated all the ChatterResponse message on the server-side in an array and then sent the array all as part of the function return, I would declare the function signature as:
rpc Chatter (ChatterRequest) returns (repeated ChatterResponse) {}
WHERE
repeated is a keyword that indicates an array of ChatterResponse messages.
Differentiating between the use of the keywords stream and repeated might seem like an inconsequential decision but it's not. Imagine that for some reason the result of the function Chatter is 500 million ChatterResponse messages, which is over 1 gigabyte of data. When a stream is in play, a remote client can process the results of the function as each ChatterResponse message comes in from the HTTP/2 connection. However, when the keyword, repeated is used and the whole array is returned from the function Chatter, the client needs to wait for over 1 gigabyte of data to download before processing can take place. Waiting for the download to complete can cause a myriad of problems all the way from process blocking to memory overload. However, this is not to say that returning entire arrays of data should be avoided. Choosing between working with a stream of data or an entire array is a decision that is appropriate to the particular use case at hand. Fortunately, gRPC offers the flexibility to support either technique.
Putting it All Together
gRPC is an important framework on the API development landscape. The use of Protocol Buffers, which is foundational to the gRPC specification offers a way to facilitate lightning-fast data transfers over the network. Also, because gRPC is intended to be run over HTTP/2, developers and consumers of gRPC APIs can enjoy the flexibility and power that comes with the streaming capabilities inherent in the HTTP/2 protocol.
There's a lot of benefit to using gRPC. However, there are tradeoffs. Working with gRPC requires a good deal of programming acumen. While other API technologies such as REST make it possible for a developer who is well-versed in the principles of HTTP to be productive, gRPC requires a lot more. You need to know how to serialize and deserialize information into binary data using Protocol Buffers and you need to be familiar with working with streams. While it's true there are many libraries that will do a lot of this work for you, the fact remains that even writing a simple client to consume data from a gRPC API requires a lot of know-how. But, if you're in an enterprise where nanosecond differences in speed could make a difference, absorbing the significant learning curve is a price well worth paying.
gRPC offers a lot and it's not going away. More companies are using it every day. Eventually, it will become an expected skill set among employers, on par with other known technologies such as REST, AJAX, and GraphQL.
Coming Up Next
The next installment of this series will take an in-depth look at how to develop a full-fledged gRPC application that has both client and server components.