When most people think of APIs, they think of a backend access point for client-server interactions in a distributed application. For many situations, this is indeed its purpose. But, an API can be much more than an interface between server-side logic and public consumers of that logic. For example, it is entirely possible to make it so that an API layer serves as the master control center for all activity taking place inside and outside a computing domain. In other words, an API layer can be the one ring that rules them all, which is the approach taken by Kubernetes.
Kubernetes, the workload and container orchestration technology created by Google, but now maintained by the Cloud Native Computing Foundation (CNCF), has a component called the API Server that controls much of the activities inside and outside a Kubernetes installation. Using an API as the one ring to rule the entirety of a Kubernetes installation is an interesting approach to system design and one well worth investigating.
In this article, we're going to do just that. We're going to look at the basics of the Kubernetes architecture and then we're going to look at how the API Server controls the components within that architecture. Finally, we're going to look at how to make a Kubernetes installation's API Server fault-tolerant.
Understanding the Kubernetes Architecture
Kubernetes started out at Google as an internal tool called the Borg System. The first version of Kubernetes was released to the public in 2015. It was turned over to the CNCF in 2016 where it is maintained today. (The CNCF is the result of a collaborative partnership between Google and the Linux Foundation.) The entire source code for Kubernetes is available for free on GitHub, which is quite a giveaway considering the complexity of the technology and the millions of dollars it must have taken to develop it.
As mentioned above, Kubernetes is a workload and container orchestration technology. What makes Kubernetes so powerful is that it's designed to manage very big applications that run at massive scale. Typically these applications are made up of tens, hundreds, maybe thousands of loosely coupled components that run on a collection of machines.
A collection of machines running controlled Kubernetes is called a cluster. A Kubernetes cluster can be made up of tens, hundreds, or even thousands of machines. A cluster can have any combination of real or virtual machines
The Cluster as the Computing Unit
Developers can conceptualize the cluster as a single computing unit. A Kubernetes cluster might be composed of a hundred machines, but the developer knows almost nothing about the composition of the underlying cluster. All work is conducted in terms of the Kubernetes cluster as an abstraction. Hiding the internals of cluster dynamics is important because a Kubernetes cluster is ephemeral. Kubernetes is designed so that the composition of the cluster can change at a moment's notice, but such change does interfere with the operation of the applications running on the cluster. Adding a machine to a Kubernetes does not affect the applications running on the cluster. The same is true when a machine is removed from the cluster.
Just as a Kubernetes cluster can scale machines up and down on-demand, so too can an application running on the cluster. All this activity is completely opaque. Both the applications in the cluster as well as services and other applications using the cluster know nothing about the internals of the cluster. For all intents and purposes, a Kubernetes cluster can behave like one very, very big computer.
The ephemeral nature of Kubernetes makes it a very powerful computing paradigm. But, along with such power comes a great deal of complexity. Kubernetes has a lot of moving parts that need to be managed. This is where the API Server, which we'll talk about in a moment, comes into play. But, first let's take a look at the components that make up a Kubernetes cluster.
Containers and Pods
The basic unit of computational logic in Kubernetes is the Linux container. You can think of a container as a layer of abstraction that provides a way to run a process on a computer in a manner that virtually isolates the process from all other processes.
For example, you can have a number of Nginx web servers running simultaneously, in an isolated manner, on a single machine by running each Nginx instance in a container. Each container can have its own CPU, memory, and storage allocations. And although a container will "share" resources in the host operating system, the container is not heavily intertwined with the host OS. The container thinks it has its own file system and network resources. Thus, should something go wrong and you need to restart or destroy one of the Nginx servers, it's just a matter of restarting or destroying the container, which in some cases takes no more than a fraction of a second. If you were running these Nginx servers directly on the host machine without the intermediation of the container technology, removing and reinstalling a host might take seconds, if not minutes. And, if there is corruption in the host file system, administering the fix and restarting the host machine can well beyond a minute or two.
Isolation and easy administration are but two of the reasons why containers are so popular and why they are foundational to Kubernetes.
A developer programs a piece of logic that is hosted in a container. For example, the logic could be some sort of Artificial Intelligence algorithm written in GoLang. Or, the logic could be Node.js code that accesses data in a database and transforms it into JSON that's returned to the caller. The possibilities of the logic that can be hosted in a container are endless.
Kubernetes organizes one or many containers into a unit of abstraction called a pod. The name, pod, is special to Kubernetes. A pod presents its container(s) to the Kubernetes cluster. The way that the logic in a pod is accessed is by way of a Kubernetes service. (See Figure 1 below.)
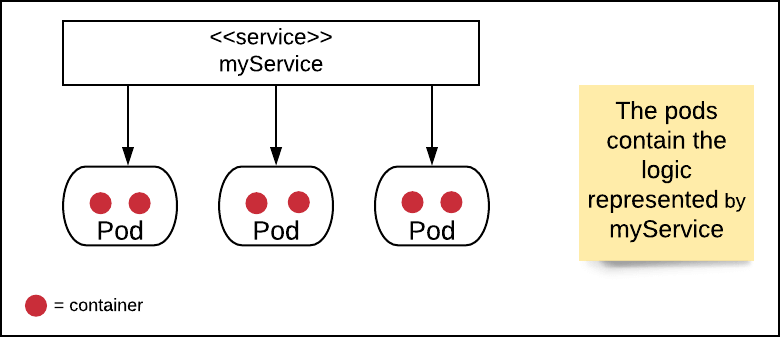
Figure 1: In Kubernetes, a pod contains the logic that is represented by an associated service
Services represent the logic of the pod(s) to the network. Let's take a look at how the representation is facilitated.
Understanding Services and Pods
Developers or Kubernetes admins configure the service to bind it to pods that have the relevant logic. For all intents and purposes, a service represents the "pod logic" to other services internal to the Kubernetes cluster and to users and programs external to the Kubernetes cluster.
Kubernetes uses labeling to bind a Service to one or many pods. Labels are foundational to the way services and pods are described within Kubernetes.
There are two ways to create a service or pod in Kubernetes. One way is to use the Kubernetes client named kubectl to invoke the creation of a pod or service directly at the command line. Listing 1 below shows an example of using kubectl to create a pod.
kubectl run pinger --image=reselbob/pinger --port=3000Listing 1: Creating a pod named pinger that uses the Docker container image, reselbob/pinger
Listing 2 shows how to use kubectl at the command line to create a service that uses the pod created above in Listing 1.
kubectl expose pod pinger --name=myservice --port=3000 --target-port=3000Listing 2: Creating a service named myservice that listens on port 8001 and is bound to a pod named pinger
Using kubectl at the command line to create pods and services is called the imperative method. While the imperative method is useful for experimenting with Kubernetes, at the professional level, manually adding pods and services to a cluster is frowned upon. Rather, the preferred way is to use the more programmatic declarative method.
The declarative method is one in which a developer or admin creates a configuration called a manifest file that describes the given pod or service. (Typically a manifest file is written in YAML, although JSON can be used too.) Then the developer, admin or some type of automation script uses the kubectl sub-command apply to the apply configuration setting in the manifest file to the cluster. Listing 3 below shows a manifest file with the arbitrary name, my_pod.yaml, that will create the pinger pod as created earlier using the imperative method.

Listing 3: The manifest file to create a pod that has the container, pinger
Once the manifest file is defined, we can create the pod declaratively like so:
kubectl apply -f ./my_pod.yamlOnce the pod is created, we then create a manifest file with the arbitrary name, pinger_service.yaml, as shown in Listing 4 below:

Listing 4: The manifest file that defines a service that is bound to pods that have the labels, app: pinger and purpose: demo
To create the service, pinger_service in the Kubernetes cluster, we apply the manifest file like so:
kubectl apply -f ./my_service.yamlStill, the outstanding question is, how does the service, pinger_service actually bind to the pod, pinger_pod. This is where labeling comes in.
Notice lines 5 to 7 in Listing 3 that describes the pod manifest file. You'll see the following entry:
labels:
app: pinger
purpose: demoThese lines indicate that the pod has been configured with the two labels as key and value pairs. One label is app, with the value pinger. The other label is purpose with the value, demo. The term "labels" is a Kubernetes reserved word. However, the labels app: pinger and purpose: demo are completely arbitrary.
Kubernetes labels are important because they are the way by which to identify the pod within the cluster. In fact, the service will use these labels as its binding mechanism.
Take a look at lines 5 to 8 in Listing 4 that describes the service manifest file. You'll see the following entry:
selector:
app: pinger
purpose: demoThe term "selector" is a Kubernetes reserved word that indicates the labels by which the service will bind to constituent pods. Remember, the manifest file, my_pod.yaml above publishes two labels, app: pinger and purpose: demo. The selectors defined in my_service.yaml make the service act if it's saying, "I am configured to go out into the cluster and look for any pods that have the labels app: pinger and purpose: demo. I will route any traffic coming into me onto those pods."
Granted, the analogical lookup statement made by the service above is simplistic. There's a lot of work that happens under the covers in terms of discovering the IP address of a pod and load balancing against a collection of pod replicas to make the service to pod routing work. Still using labels is the way Kubernetes binds a pod(s) to a service. It might be simple, but it works even at web-scale!
The Ephemeral Nature of Kubernetes
Understanding the relationships between containers, pods, and services are essential for working with Kubernetes, but there's more. Remember, Kubernetes is an ephemeral environment. This means that not only can machines be added and removed from the cluster on demand, but so too can containers, pods, and services. As you might imagine, keeping the cluster up and running properly requires an enormous amount of state management, as you'll see when we describe in an upcoming scenario that illustrates the ephemeral aspects of Kubernetes. (In that scenario, we'll create multiple pods that are guaranteed by Kubernetes to always run, even when something goes wrong with the host machine or with the pods themselves.)
In addition to containers, Pods, and Services, there are many other resources — actual, virtual, and logical — that can run in a Kubernetes cluster. For example, there are ConfigMaps, Secrets, ReplicaSets, Deployments, and Namespaces to mention a few. (Go here to read the full documentation for Kubernetes API resources.)
The important thing to understand is that there can be hundreds, if not thousands of resources in play on any Kubernetes cluster at any given time. The resources are acting in concert and changing state continuously.
Here's an example of but one instance of a resource changing state. When a pod created by a Kubernetes Deployment fails, it will be replenished automatically by Kubernetes. (You'll read about the details of a Kubernetes Deployment in the next section.) The new pod might be replenished on the same virtual machine (aka "node") as the failing one or might be replenished on a newly provisioned virtual machine altogether. Kubernetes will keep track of all the details that go with the replenishment — IP address of the host machine, IP address of the pod itself and the Kubernetes Deployment controlling the pod, to name just a few of the details tracked. All the details that go with the pods, the deployment, services using the pods, and the nodes hosting the pods are considered to be part of the state of the cluster.
As you can see, just moving a pod from one node to another is a significant state change in the cluster. This action is just one of hundreds of state changes that can be happening at any given time. Yet, Kubernetes knows about everything going on in the cluster, all the time, over the entirety of the network on which the cluster is running. The question is, how? The answer is in the control plane.
Understanding the Kubernetes Control Plane
As mentioned above, Kubernetes is designed to support distributed applications that are spread out over a number of machines, real or virtual. The machines might be located in the same datacenter. It's just as possible that the collection of machines that make up the cluster might be distributed across a national computing region or even worldwide. Kubernetes is designed to support this level of distribution.
In Kubernetes parlance, a machine is called a node. In a Kubernetes cluster, there are two types of nodes. There is the controller node and there are the worker nodes. The controller node does as its name implies. It controls activities in the cluster and coordinates activities among the worker nodes. The worker nodes are as their name implies; they do the actual work of running containers, pods, and services.
The controller node contains a number of components that are required to keep the cluster up and running as well as manage the continuously changing state of the cluster. These components make up what's called the "control plane." (See Figure 2, below)
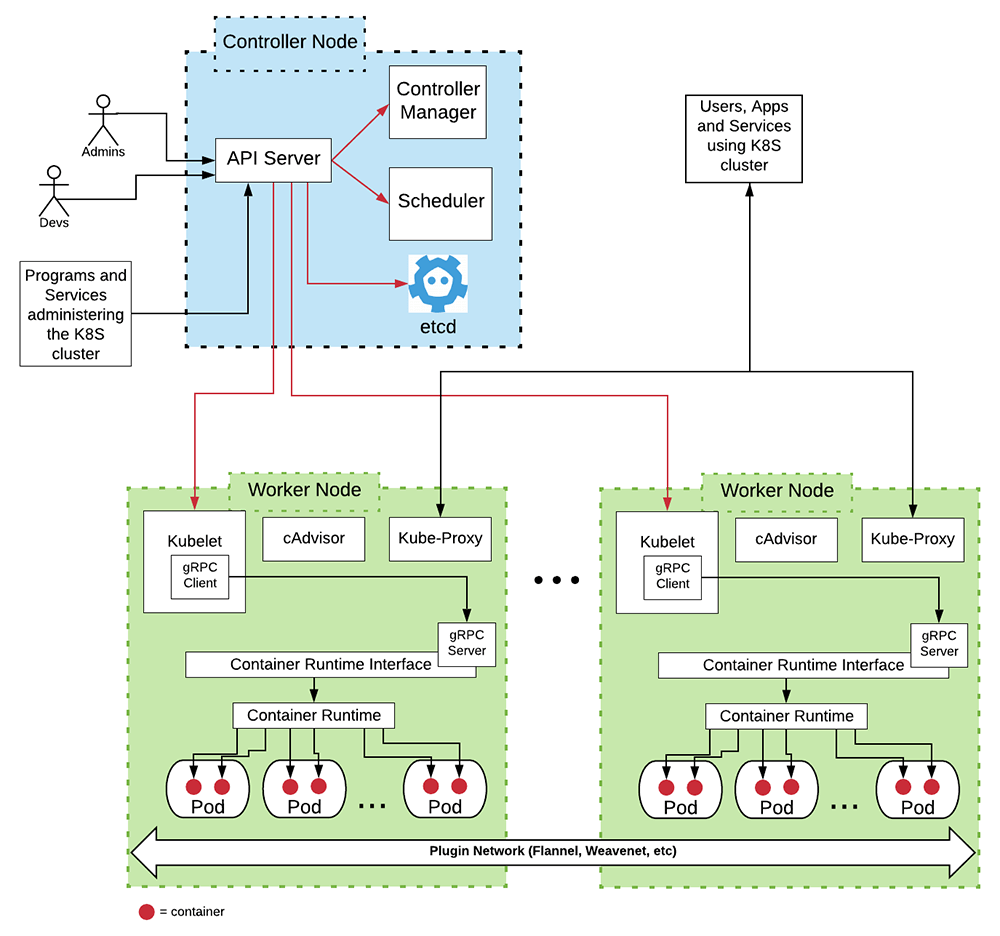
Figure 2: The basic architecture of a Kubernetes Cluster
Table 1 below describes the components in both the control node and worker nodes. For a more in-depth discussion, you can read the Kubernetes documentation that describes the control plane and the components that are installed on each worker node, here.
| Component | Location | Purpose |
|---|---|---|
| API Server | Controller Node | The API Server is the primary interface into a Kubernetes cluster and for components within the given Kubernetes cluster. It's a set of REST operations for creating, updating and deleting Kubernetes resources within the cluster. Also, the API publishes a set of endpoints that allow components, services, and administrators to "watch" cluster activities asynchronously. |
| etcd | Controller Node | etcd is the internal database technology used by Kubernetes to store information about all resources and components that are operational within the cluster. |
| Scheduler | Controller Node | The Scheduler is the Kubernetes component that identifies a node to be the host location where a pod will be created and run within the cluster. Scheduler does NOT create the container's associated with a pod. Scheduler notifies the API Server that a host node has been identified. The kubelet component on the identified worker node does the work of creating the given pod's container(s). |
| Controller Manager | Controller Node | The Controller Manager is a high-level component that controls the constituent controller resources that are operational in a Kubernetes cluster. Examples of controllers that are subordinate to the Controller Manager are replication controller, endpoints controller which binds services to pods, namespace controller, and the serviceaccounts controller. |
| kubelet | Worker Node | kubelet interacts with the API Server in the controller node to create and maintain the state of pods on the node in which it is installed. Every node in a Kubernetes cluster runs an instance of kubelet. |
| Kube-Proxy | Worker Node | Kube-proxy does Kubernetes network management activity on the node upon which it is installed. Every node in a Kubernetes cluster runs an instance of Kube-proxy. Kube-proxy provides service discovery, routing, and load balancing between network requests and container endpoints. |
| Container Runtime Interface | Worker Node | The Container Runtime Interface (CRI) works with kubelet to create and destroy containers on the node. Kubernetes is agnostic in terms of the technology used to realize containers. The CRI provides the abstraction layer required to allow kubelet to work with any container runtime operational within the node. |
| Container Runtime | Worker Node | The Container Runtime is the actual container daemon technology in force in the node. The Container Runtime does the work of creating and destroying containers on a node. Examples of Container Runtime technologies are Docker, containerd, and CRI-O, to name the most popular. |
The API Server as the Central Point of Command
As mentioned above, Kubernetes takes a "one ring to rule them all" approach to cluster management and that "one ring" is an API Server. In general, all the components that manage a Kubernetes cluster communicate with the API server only. They do not communicate with each other. Let's take a look at how this works.
Imagine a Kubernetes Admin who wants to provision 3 identical pods into a cluster in order to have fail-safe redundancy. The admin creates a manifest file that defines the configuration of a Kubernetes Deployment. A Deployment is a Kubernetes resource that represents a ReplicSet of identical pods that are guaranteed by Kubernetes to all be running all the time. The number of pods in the ReplicaSet is defined when the Deployment is created. An example of a manifest file that defines such a Deployment is shown below in Listing 5. Notice the Deployment has 3 pods in which each pod has a container running an Nginx web server.
--
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80Listing 5: A manifest file that creates 3 pods with each pod hosting an Nginx container.
After the Kubernetes Admin creates the manifest file for the Deployment, the admin submits it to the API Server by invoking the Kubernetes client CLI tool, kubectl like so:
kubectl apply -f mydeployment.yamlWHERE
- kubectl is the Kubernetes command-line tool for interacting with the API server
- apply is the subcommand used to submit the contents of the manifest file to the API server
- -f is the option that indicates the configuration information is stored in a file according to the filename that follows
- mydeployment.yaml is the fictitious filename used for example purposes that has the configuration information relevant to the Kubernetes resource being created
kubectl sends the information in the manifest file onto the API server via HTTP. The API Server then notifies the components that are necessary to complete the provisioning. This is where the real action begins.
Anatomy of Kubernetes Pod Creation
Figure 3 below illustrates the work that gets done when an administrator creates a Kubernetes resource using the kubectl command line tool. (In this case, the administrator is creating a Kubernetes Deployment.) The details of the illustration demonstrate the central role that the API Server plays in a Kubernetes cluster in general and the control plane in particular. Let's take a look at the details.
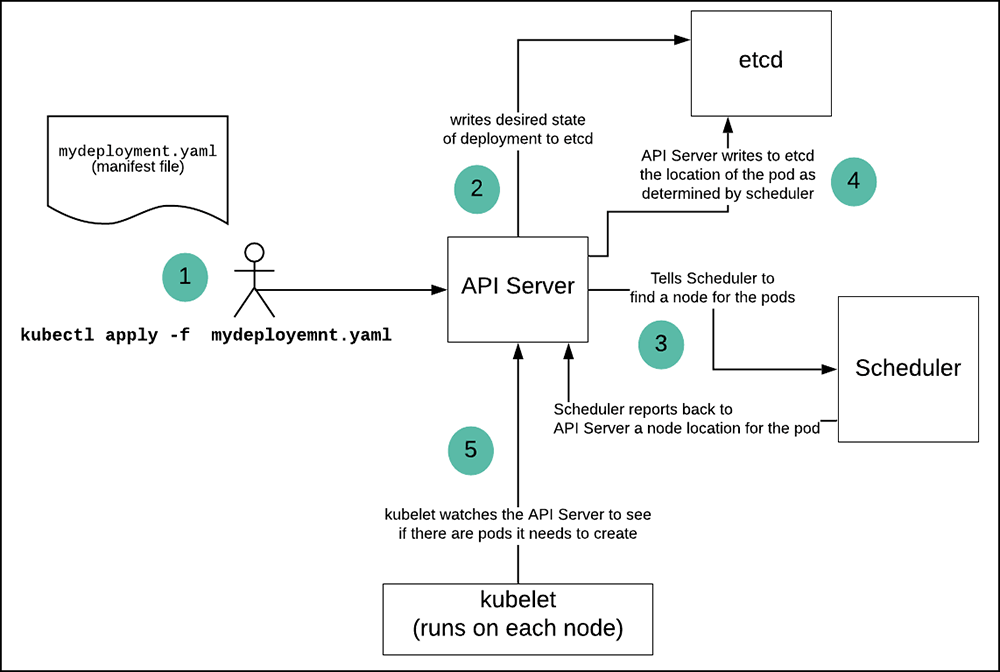
Figure 3: The process for creating pods in a Kubernetes Deployment using kubectl
In the scenario above in Figure 3 at Callout (1), a Kubernetes administrator submits the contents of a manifest file to the API Server running on a Kuberentes cluster by entering, kubectl apply -f mydeployment.yaml at the command prompt. (The contents of the manifest file is displayed above at Listing 5.) The API Server enters the configuration information about the Deployment into etcd (Callout 2). etcd is the internal database that stores all the state information about everything in the cluster. In this case, information about the Deployment and the number of pod replicas required is stored in etcd. Also, the template information upon which the pods in the Deployment will be configured is stored too.
After the deployment information is stored in etcd, the API Server notifies the Scheduler to find nodes to host the pods defined by the Deployment. (Callout 3) The Scheduler will find nodes that meet the pods' requirements. For example, the pods might require a node that has a special type of CPU or a particular configuration of memory. The Scheduler is aware of details of all the nodes in the cluster and will find nodes that meet the requirement of the pod. (Remember, information about every node in the cluster is stored in etcd.)
The Scheduler identifies a host node(s) for the deployment and sends that information back to the API Server. (Callout 4) The Scheduler does NOT create any pods or containers on the node. This is the work of kubelet.
In addition to publishing a typical REST HTTP interface, the API Server also has asynchronous endpoints that act as queues in a PubSub message broker. Every node in a Kubernetes cluster runs an instance of kubelet. Each instance of kubelet "listens" to the API Server. The API Server will send a message announcing a request to create and configure a pod'd container(s) on a particular Kubernetes node. The kubelet instance running on the relevant node picks up that message from the API Server's message queue and creates the container(s) according to the specification provided. (Callout 5) kubelet creates containers by interacting with the Container Runtime Interface (CRI) described above in Table 1. The CRI is bound to the specific container runtime engine installed on the node.
kubelet sends the API Server status information that the container(s) has been created along with information about the container(s)'s configuration. At this point, kubelet will keep the container healthy and will notify the API Server if something goes wrong.
As you can see, the API Server is indeed the one ring that rules them all in a Kubernetes cluster. Yet, having the API Server be central to much of the critical processing activity that takes place on the cluster creates a single point of failure risk. What happens if the API Server goes down? If you're a company such as Netflix this is not a trivial problem. It's catastrophic. Fortunately, the problem is solved by using controller node replicas.
Ensuring the that the API Server is Always Available
As mentioned above, Kubernetes ensures the high availability of the API Server by using controller node replicas. This is the analogical equivalent of creating pod replicas within a Kubernetes Deployment. Only, instead of replicating pods you're replicating controller nodes. All the controller nodes live behind a load balancer and thus, traffic is routed accordingly.
Setting up a set of controller node replicas requires some work. First, you'll install kubelet, kubectl and kube-proxy and the container runtime on every node in the cluster, regardless of whether the node will be a controller node or a worker node. Then you will need to set up a load balancer to route traffic to the various controller nodes, but after that, you can use Kubernetes command-line tool, kubeadm to configure nodes as a controller and worker nodes accordingly. There is some work to do in terms of making sure all the configuration settings are correct at the command line. It requires attention, but it's not overly detailed work.
In terms of state storage, etcd is still the only authority for the state of the cluster. In a multi-controller node configuration, each instance of etcd on the local machine forwards read and write requests onto a shared cluster of etcd servers set up in a quorum configuration. In a quorum configuration, making a write to the database happens when a majority of the etcd servers in the cluster approve the change.
Does setting up a etcd in a quorum configuration in which are spread out over the network create latency issues in terms of read and write performance? Yes, it does. However, according to the Kubernetes maintainers, the latency period between machines in the same Google Compute Engine region is less than 10 milliseconds. Still, when doing operations that are extremely time-sensitive, it's wise to make it so all the machines in the cluster are at least in the same data center, optimally within the same row of server racks in the data center. In extremely time-sensitive situations the physical distance between machines counts!
Putting It All Together
APIs are becoming the critical linchpin in modern application architecture. They can make applications easy to scale and easy to maintain. Yet an API can do more than being the public representation of application logic to client-side consumers. As we've seen from the analysis we've presented in this piece, Kubernetes API Server is a prime example of using APIs to control all operational aspects a software system. The Kubernetes API Server does a whole lot more than deliver data. It manages system state, resource creation, change notification as well as access to the system. It is indeed the one ring that rules them all.
The Kubernetes API Server is a complex technology, no doubt. But the fact that Kubernetes is so widely used throughout the industry lends credence to the architectural style of using APIs as a system control hub. Using an API as a one ring to rule approach to implementing software systems is a clever design sensibility and one well worth considering.